gMLPの論文の概要を把握する
gMLPが話題のようなので、論文の概要を把握できればということで当記事にまとめます。
[2105.08050] Pay Attention to MLPs
以下、目次になります。
1. gMLPの概要(Abstract、Introductionの確認)
1-1 Abstractの確認
1-2 Introductionの確認(Section1)
2. 論文の重要なポイントの抜粋
2-1. Model(Section2)
2-2. Image Classification(Section3)
2-3. Masked Language Modeling with BERT(Section4)
2-4. Conclusion(Section5)
3. まとめ
1. gMLPの概要(Abstract、Introductionの確認)
1-1 Abstractの確認
1-1節では論文のAbstractを確認します。

上記がgMLPの論文のAbstractです。以下、簡単に重要事項についてまとめます。
・Transformerはここ数年におけるDeepLearningの構造の中でも重要なトピックの一つである
・この研究におけるgMLPはgatingを使うMLPのみを用いることでTransformerと同等のパフォーマンスを実現した
・Vision-Transformerにおけるself-attentionはそれほど重要でない可能性がある
・BERTに関連するいくつかのdownstream tasksにおいて、gMLPはTransformerを上回った
・gMLPはTransformerと同様にスケールさせることができる
Abstractについて概ね把握できたので1-1節はここまでとします。
1-2 Introductionの確認(Section1)
1-2節ではIntroductionの記載を確認します。

第一、第二パラグラフでは、Transformer関連の研究のブレークスルーについて書かれた後に、Transformer構造の二つの重要なコンセプトについて紹介されています。それぞれ「(1)リカレント構造の必要ない構造」、「(2) トークン(単語など)間で空間的に情報の集約を行うmulti-head self-attentionブロック」の二つが挙げられています。一方でこの際に生じるinductive biasについて論じられており、それに関連してMLPでは任意の関数を表すことができるとされています。
inductive biasについては下記で確認したGraph Networkが大元になっていると思われるので、気になる方は下記も確認してみていただけたらと思います。
このinductive biasについて考えた際に「self-attentionはTransformerの著しい効率化について寄与しているか」がここでopen question(考察のテーマくらいの認識で良さそうです)になるとされています。

第三パラグラフでは、attentionを用いないMLP-basedのgMLPをTransformerの代替に考えると記載されており、続く第四パラグラフではImageNetなどの画像タスクに関する取り組みのDeiTやViTに比較してgMLPが同等のパフォーマンスを示したことが記載されています。


第五、第六パラグラフでは、gMLPのBERTへの適用について議論されており、第五パラグラフではpretrainingについて、第六パラグラフではfinetuningについてそれぞれ記載されています。
BERTのMLM(Masked Language Modeling)などについて知りたい方は下記の3章でまとめましたので、こちらも確認してみていただけたらと思います。

第七パラグラフでは、Introductionの総括も兼ねて、この研究で行った実験の結果を元に考えると「self-attentionはそれほど重要なモジュールではないのではないか」と問題提起が行われています。
2. 論文の重要なポイントの抜粋
2-1. Model(Section2)
2-1節ではSection2のModelの重要な点について確認します。


まず上記が冒頭部の記載ですが、(1)式〜(3)式でgMLPの大枠の数式について記載されています。が系列の長さ(
とされることもあります)、
が分散ベクトルの次元(Word2vecと同様です)を表すことは抑えておくと良いと思います。ここで(2)式が恒等写像(identity mapping)であればこの式はオーソドックスなFFN(Feed Forward Networkの意味ですが、Multi Layer Perceptronの意味もここでは含んでいると解釈する方が良いと思います)を表すとされています。また、(1)の式は Transformerのパラメータ演算(FFN)と同様であることも記載されています。
ここで(2)式の関数がトークン間の空間的な相互作用(spatial interactions across tokens)を表すとされており、ここの処理でTransformerのself-attentionを代替するというのがこの論文のテーマであると考えて良いかと思います。
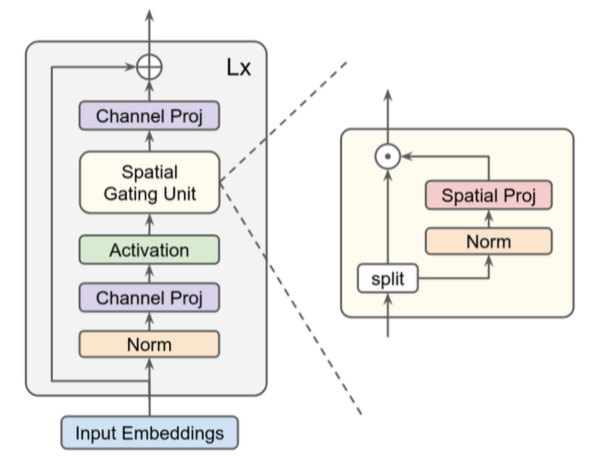
また、処理の全容に関しては、下記のFigure1にまとめられています。
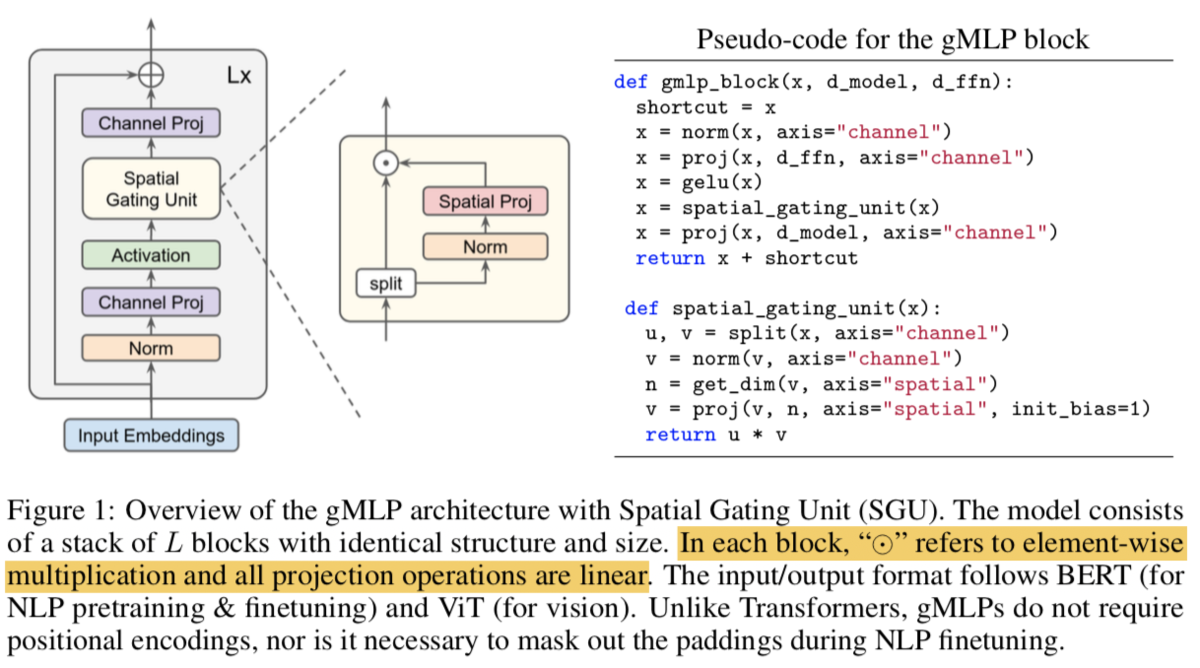
上記のグレーの四角形の中に(1)式〜(3)式の処理が記載されており、gMLPにおける特殊な処理である関数は黄色のSpatial Gating Unitで表されています。

Spatial Gating Unitに関してはSection2-1で詳しく記載されています。(5)式が関数の処理であり、ここで用いられている
の定義については(4)式で示されています。ここで
は
に対応するので
行
列、
はトークン列の長さに対応して
行
列であることは抑えておくと良いと思います。
ここではattentionの処理のように、どのくらい他のトークンの値を参考にするかを表した行列と考えておくのが良さそうです。また安定化にあたっては
の初期値を
近辺、
の初期値を
にすると学習が安定したと記載されています。また、(5)式の代わりに
を分割した
と
を用いた(6)式を用いると効率的だったことについても記載されています。
2-2. Image Classification(Section3)
2-3. Masked Language Modeling with BERT(Section4)
2-4. Conclusion(Section5)
この記事では省略します。
3. まとめ
この論文ではself-attentionを用いないとありましたが、「self-attentionを用いる用いない以上にinductive biasをどのように考慮して全体を設計するのかに今後の研究にあたっては重視されそうだ」と解釈する方が良いのではと思われました。
そのため考察にあたってはあまり細かい定義を気にし過ぎずに、以前の記事でも取り扱った"Relational inductive biases, deep learning, and graph networks"の研究などを元に統合的に整理しつつinductive biasの設計について考える方が良いのではないかと思います。
[1806.01261] Relational inductive biases, deep learning, and graph networks
この辺の構造に関しては色々とアイデアがあると思いますので、議論がある程度収束するまではあまり細かい構成を考え過ぎなくても良いのではという印象でした。