TransGAN|DeepLearningを用いた生成モデルの研究を俯瞰する #5

当シリーズでは生成モデルの研究や実装の俯瞰を行います。#4ではSemi-Supervised GAN(Semi-Supervised Learning with Generative Adversarial Networks)について取り扱いました。
#5では、GANにTransformerの考え方を導入した研究である、TransGAN(TransGAN: Two Transformers Can Make One Strong GAN)について取り扱います。
[2102.07074] TransGAN: Two Transformers Can Make One Strong GAN
以下目次になります。
1. TransGANの概要(Abstract、Introductionの確認)
1-1 Abstractの確認
1-2 Introductionの確認(Section1)
2. 論文の重要なポイントの抜粋
2-1. Relative Works(Section2)
2-2. Technical Approach: A Journey Towards GAN with Pure Transformers(Section3)
2-3. Comparison with State-of-the-art GANs(Section4)
2-4. Conclusions, Limitations, and Discussions(Section5)
3. まとめ
1. TransGANの概要(Abstract、Introductionの確認)
1-1 Abstractの確認
1-1節では論文のAbstractについて簡単に確認を行います。

上記がAbstractの記載ですが、要旨を下記にまとめます。
・TransformerのComputer Visionの分野への導入が取り組まれているが、GAN(generative adversarial networks)についても取り組むにあたってTransGANの研究が行われた。
・畳み込みを一切用いないで(completely free of convolutions)Transformerの処理だけに基づくarchitectureのTransGANを構築した。
・TransGANは段階的に解像度を上げる(progressively increases feature resolution)ことでmemory-friendlyなTransformer構造に基づき構築されている。
基本的には「TransformerをGANのタスクに導入した」が主題ですが、"progressively increases feature resolution"の記載は以前取り扱ったProgressive GAN(Progressive growing of gans for improved quality, stability, and variation)の研究を指していることは抑えておくと良いと思います。
Abstractについて大まかに確認できたので1-1節はここまでとし、続く1-2節では論文のSection1のIntroductionについて確認します。
1-2 Introductionの確認(Section1)
1-2節ではIntroductionをパラグラフ単位で確認を行います。

第一パラグラフでは、GANの初期研究の成功や、一貫して取り組まれてきた学習にあたっての安定化(stabilizing GAN training)の課題について紹介されています。
ここで、"Radford et al., 2015"は以前取り扱ったDCGAN(Deep Convolutional GAN)であることは抑えておくと良いと思います。

第二パラグラフでは、パフォーマンスの向上にあたって、backbone(特徴量抽出器と理解すれば良いです)に関するablation study(条件を一つずつ変えて行う実験)によりResNetやそれ以外のbackboneについて試したとされています。また、他の取り組みとして、self-attentionやstyle-based generator(StyleGAN)、自己回帰Transformerなどが挙げられています。


第三パラグラフでは、GANのbackboneを選定するにあたっての共通認識(commonsense)として、CNNの構造が基本とされていたことについて記載されています。畳み込みは強力なinductive bias(前提の構造を決めることによって学習力を高めることができるが、これをinductive biasと呼んでいる)を持つため、Computer Visionにおいては基本的に畳み込みの構造が用いられてきました。

続くパラグラフでは、畳み込みの問題点の"local receptive field"について記載されています。これによって、広い範囲の依存性(long-range dependencies)が取り扱えないとされています。これはCNNがself-attentionやnon-localな演算を用いた研究に比べ、大域的な統計量(global statistics)を取得できないという点を示唆していると考えて良いかと思います。
以下は、何箇所か抜粋して確認します。

上記はこれまで確認したCNNの問題点を解消するにあたって、pure Transformerを用いた構造をTransGANとしたとあります。

また、この研究のCotributionは上記にまとめられています。
2. 論文の重要なポイントの抜粋
2-1. Relative Works(Section2)
Generative Adversarial Networks(Section2-1)、Visual Transformer(Section2-2)、Transformer Modules for Image Generation(Section2-3)でそれぞれまとめられています。
詳しく確認すると冗長になると思われるのでここでは省略します。
2-2. Technical Approach: A Journey Towards GAN with Pure Transformers(Section3)
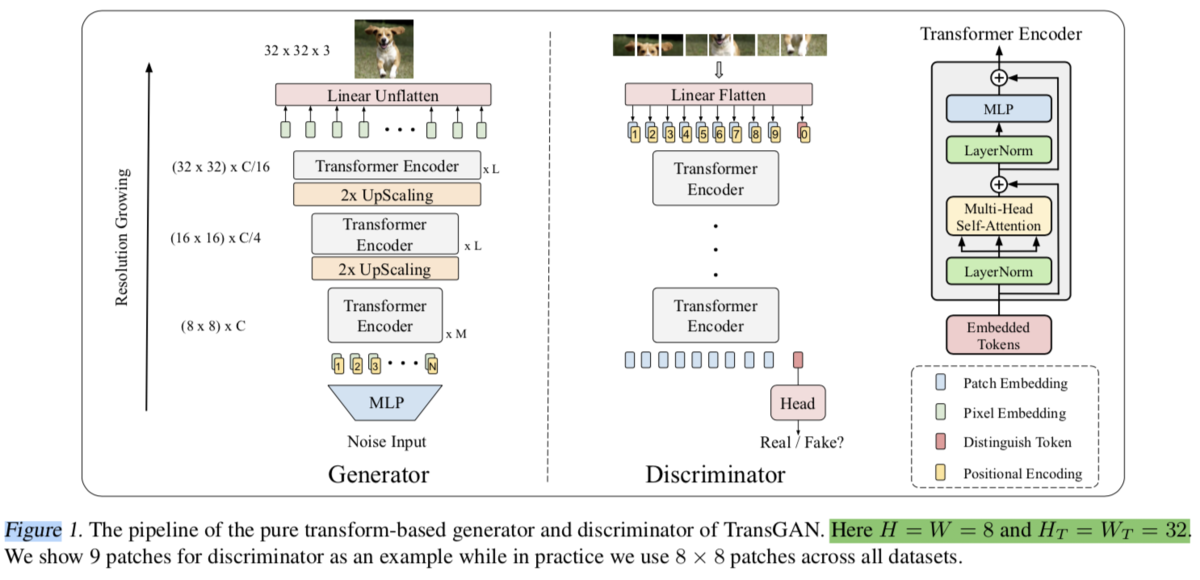
処理の全体像は上記です。Progressive GAN(Progressive growing of gans for improved quality, stability, and variation)とVisionTransformer(AN IMAGE IS WORTH 16X16 WORDS)が把握できていれば、処理の概要が把握できるかと思います。

また、論文のFigure2ではgeneratorのlossに超解像(SuperResolution)のlossを加えたことについて記載されています。

論文のFigure3では、CNNライクなinductive biasを導入するにあたって、段階的にReceptive Fieldを増やしていくことについて表されています。これによってCNNの構造的利点を活かしつつ大域的な処理も可能となるように試みたと理解して良いと思います。(関連の記載はSection3-4のLocality-Aware Initialization for Self-Attentionで記載されています)
2-3. Comparison with State-of-the-art GANs(Section4)
2-4. Conclusions, Limitations, and Discussions(Section5)
当記事では省略します。
3. まとめ
#5ではTransGAN(TransGAN: Two Transformers Can Make One Strong GAN)について取り扱いました。
#6以降でも引き続き関連の研究について確認できればと思います。