【論文確認】Visual Transformers

当記事では主に汎用言語処理の分野で数多く関連研究がなされているTransformerを画像認識に取り入れた研究であるVisual Transformersの論文(Visual Transformers: Token-based Image Representation and Processing for Computer Vision)を確認していきます。
以下、目次になります。
1. Visual Transformersの概要(Abstract、Introductionの確認)
1-1 Abstractの確認
1-2 Introductionの確認
2. 論文の重要なポイントの抜粋
2-1 Related work(Section2)
2-2 Visual transformer(Section3)
2-3 Using visual transformers to build vision models(Section4)
2-4 Experiments(Section5)
2-5 Conclusions(Section6)
2-6 Broader impact discussion(Section7)
3. まとめ
1. Visual Transformersの概要(Abstract、Introductionの確認)
1-1 Abstractの確認
1-1節ではAbstractの内容を確認しながら概要について把握します。以下一文ずつ和訳とともに解説を行います。
Computer vision has achieved remarkable success by (a) representing images as uniformly-arranged pixel arrays and (b) convolving highly-localized features. However, convolutions treat all image pixels equally regardless of importance; explicitly model all concepts across all images, regardless of content; and struggle to relate spatially-distant concepts.
和訳:『コンピュータービジョンの分野では、(a)統一的に整列したピクセルの配列としての画像表現と、(b)高度にローカライズされた特徴量を畳み込むことで、著しい成功を達成してきた。しかしながら、畳み込みは全ての画像ピクセルをそれぞれの重要度を無視して取り扱い、内容に関わらず全ての画像における全ての概念を明示的にモデル化し、空間的距離の概念を関係付けるのに苦戦している。』
解説:『1文目はよく記載される一般論で、2文目はこの研究の取り組む課題として、畳み込み処理における重要度の取り扱いの非効率性について言及しています。』
In this work, we challenge this paradigm by (a) representing images as semantic visual tokens and (b) running transformers to densely model token relationships. Critically, our Visual Transformer operates in a semantic token space, judiciously attending to different image parts based on context.
和訳:『この研究では、(a)画像を意味的なビジュアルトークン(semantic visual token)として表現し、(b)Transformerを用いてトークンの関係性を密にモデル化することで、このパラダイムの解決に取り組んだ。トークンの意味的空間において、我々の構築したVisual Transformerを用いることで、文脈に基づく異なる画像の部分との処理が実現できた。』
解説:『Transformerはそれぞれのトークンにおける意味的類似に基づいて情報を混ぜ合わせるAttentionという考え方を用いており、その考え方を画像にも応用するにあたっての言及がなされています。FastRCNNなどで言及があるようにCNNの処理後のfeature mapはある程度処理前と処理後の位置的情報が一致し、これは畳み込み処理においてはある程度位置的情報に依存して処理が進むことを意味しています。畳み込み処理よりもTransformerにおけるAttentionの方が、広範に演算ができることは知っておくと良いかと思います。』
This is in sharp contrast to pixel-space transformers that require orders-of-magnitude more compute. Using an advanced training recipe, our VTs significantly outperform their convolutional counterparts, raising ResNet accuracy on ImageNet top-1 by 4.6 to 7 points while using fewer FLOPs and parameters. For semantic segmentation on LIP and COCO-stuff, VT-based feature pyramid networks (FPN) achieve 0.35 points higher mIoU while reducing the FPN module's FLOPs by 6.5x.
和訳:『これは一桁大きい計算を必要とするピクセルスペースのTransformerとははっきりと対照的である。高度に発展させた学習手法を用いることで、我々のVT(Visual Transformer)は畳み込みを用いた手法をはるかに上回り、ImageNetのtop-1分類において計算量やパラメータを減らしつつ4.6〜4.7ポイントResNetの正答率を上回った。LIPやCOCO-stuffにおけるセマンティックセグメンテーションにおいては、VT(Visual Transformer)ベースのFPN(feature pyramid networks)が計算量を削減しつつmIoUを0.35ポイント改善させた。』
解説:『Visual Transformerの利点や成果について言及されています。Section5のExperimentsなどに詳しく記載があるので、1-1節では省略します。』
1-2 Introductionの確認
1-2節ではIntroductionの確認を行っていきます。



第一パラグラフでは、コンピュータビジョンにおいてデファクトとして用いられている畳み込みフィルタ(convolutional filters)を用いた画像処理の概要について記載した後に、その制限(limitations)について言及されています。制限としては三つ言及されており、「1) 全てのピクセルを平等に取り扱うべきでないのに畳み込みでは取り扱っていること」、「2) 広範囲の意味的な相互作用の取り扱いを行った方が良いのにできていないこと」、「3) 疎で高次の意味的概念を取り扱うのに畳み込みは効率的ではないこと」が挙げられています。

第二パラグラフでは、第一パラグラフで言及した制限を解決するにあたって、Visual Transformerの概要について紹介を行なっています。Section3などで図などとともに言及があるのでここでは流します。

第三パラグラフでは、Visual Transformerのデモンストレーションとして行なった実験などについて記載されています。Section5などに詳しい記載があるので1-2節では省略します。
2. 論文の重要なポイントの抜粋
2-1 Related work(Section2)

Section2のRelated workでは関連研究についてまとめられています。詳細の確認については今回は省略します。
2-2 Visual transformer(Section3)
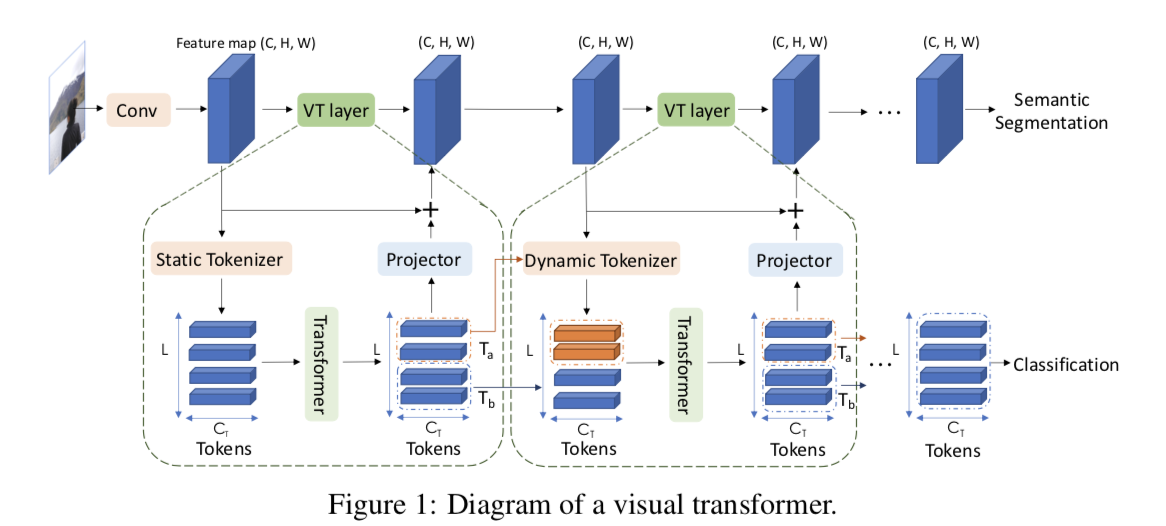
論文のFigure1では上記のようにVisual Transformerの全体像が記載されており、畳み込み処理(Conv)の後の処理として、Tokenizer(薄いオレンジ)、Transformer(薄い緑)、Projector(薄い青)の三つのモジュールがVisual Transformerを構成しているとされています。以下、この三つのモジュールの処理について確認を行います。

まずTokenizerですが、処理概要は上記のようにまとめられています。

数式は上記のように記載されており、と
がパラメータで、
が図における中心に配置されたL枚の画像を表しています。


また上記のように計算したPosition encodingを作成したVisual Tokensに加えるとされています。

次にTransformerですが、 数式(3)で処理が表されています。

Projectorについては上記のように、と
を用いて
を計算しています。第二項の行列演算については少々入り組んでいますが、右辺の第一項と第二項がともにHW行C列であることは把握しておきましょう。
2-3 Using visual transformers to build vision models(Section4)
論文のSection4ではコンピュータビジョンのモデルへのTransformerの導入にあたっての詳細についてまとめられています。

まず上記ではVisual Transformerを制御する三つのハイパーパラメータとして、feature mapのチャネル数の、Visual Tokenのチャネル数の
、Visual Tokenの数を表す
がそれぞれ紹介されています。

続くSection4-1では画像分類(image classification)へのVisual Transformerの導入として、ResNetにVisual Transformerを導入したVT-ResNetについて紹介されています。ResNet18とResNet34においては、
、
で設定すると言及されています。

Section4-2ではセマンティックセグメンテーションを実現するにあたってFPN(Feature Pyramid Network)にVisual Transformerを導入した、VT-FPNについて紹介されています。はバックボーンネットワークとして用いるResNetなどのチャネル数に依存するとされており、他のハイパーパラメータは
、
とされています。
2-4 Experiments(Section5)
Section5では有名なデータセットを用いたパフォーマンス測定の結果が記載されています。

まず上記では、ImageNetにおけるResNetとVT-ResNetの比較が行われています。VT-ResNetの方がTop-1の正答率が向上していることが読み取れます。

次に上記のTable4では、COCO-stuffとLIPを用いたセマンティックセグメンテーションの結果を示しており、mIoUの値を向上させていることが読み取れます。

また、意味的情報の可視化にあたって、各Visual TransformerにおけるAttention mapを可視化したものがFigure.5であり、教師ラベルを与えずに(without any supervision)、意味的な情報を振り分けることができるとされています。
2-5 Conclusions(Section6)
2-6 Broader impact discussion(Section7)
どちらも総括なので省略します。
3. まとめ
今回は"Visual Transformers: Token-based Image Representation and Processing for Computer Vision"の論文の確認を行なってきました。
エッジの情報などのlow-levelな情報の取り扱いに強い一方で画像全体に広がるhigh-levelな意味的情報の取り扱いに対してはあまり効率的でない畳み込み処理に対して、Visual Transformerを導入することで解決について試みた研究である、と理解しておくと良いのではないかと思います。