【論文確認】iGPT(Generative Pretraining from Pixels)
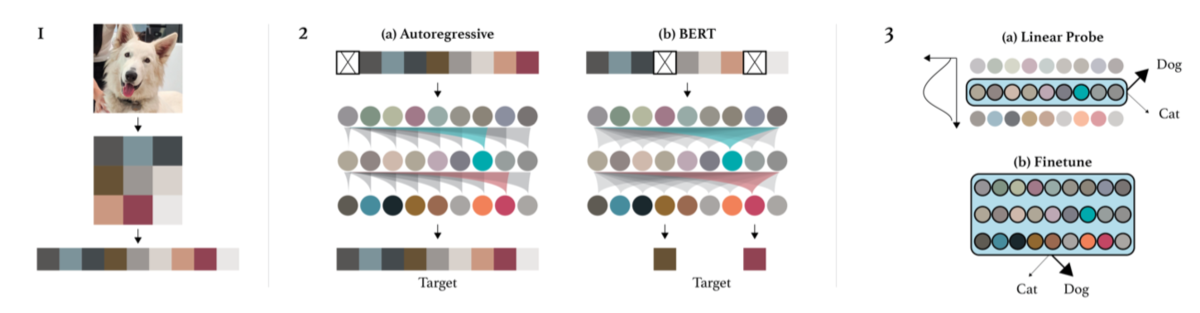
以前の記事でTransformerを画像認識に取り入れた研究であるVisual TransformersやVision Transformerの論文を確認しましたが、今回は関連論文であるiGPT(Generative Pretraining from Pixels)について確認します。
https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf
以下、目次になります。
1. iGPTの概要(Abstract、Introductionの確認)
1-1 Abstractの確認
1-2 Introductionの確認
2. 論文の重要なポイントの抜粋
2-1 Approach(Section2)
2-2 Methodology(Section3)
2-3 Experiments and Results(Section4)
2-4 Related Work(Section5)
2-5 Discussion and Conclusion(Section6)
3. まとめ
1. iGPTの概要(Abstract、Introductionの確認)
1-1 Abstractの確認
1-1節ではAbstractの内容を確認しながら概要について把握します。以下一文ずつ和訳とともに解説を行います。
Inspired by progress in unsupervised representation learning for natural language, we examine whether similar models can learn useful representations for images.
和訳:『自然言語(処理)の教師なしの表現学習における発展を受けて、我々は同様のモデルが画像においても有用な表現を学習できるかどうかを調べた。』
解説:『Transformer(2017)、BERT(2018)以降の自然言語処理における教師なしの事前学習における成果を元に画像にも適用させようということで、研究の背景や目的について言及されています。』
We train a sequence Transformer to auto-regressively predict pixels, without incorporating knowledge of the 2D input structure.
和訳:『我々は2次元の画像構造の知識を組み込むことなしに自己回帰的にピクセルを予測する系列Transformerを学習させた。』
解説:『この論文(iGPT)における手法の概要について簡単に言及されています。詳しくはSection2とSection3で記載されているのでここでは省略します。』
Despite training on low-resolution ImageNet without labels, we find that a GPT-2 scale model learns strong image representations as measured by linear probing, fine-tuning, and low-data classification. On CIFAR-10, we achieve 96.3% accuracy with a linear probe, outperforming a supervised Wide ResNet, and 99.0% accuracy with full finetuning, matching the top supervised pre-trained models. An even larger model trained on a mixture of ImageNet and web images is competitive with self-supervised benchmarks on ImageNet, achieving 72.0% top-1 accuracy on a linear probe of our features.
和訳:『ラベルなしで低解像度のImageNetにおける学習を行なったにも関わらず、GPT-2の規模のモデルがlinear probing、fine-tuning、low-data classificationで計測した際に強力な画像表現を学習することを我々は発見した。CIFAR-10においてlinear probeで96.3%の正答率となり、教師ありWide ResNetのパフォーマンスを上回り、full finetuningでは99.0%で教師あり事前学習モデルの最も良い精度と同等となった。ImageNetとWebの画像の混合によって行うより大きなモデルの学習でさえも、Top-1正答率で72.0%を獲得した。』
解説:『実験結果などについて言及されています。この記載だけでは意味が取れないところもあったので、一部省略や意訳を行いました。』
1-2 Introductionの確認
1-2節ではIntroductionの確認を行っていきます。
↓以下は後日追記予定です。
2. 論文の重要なポイントの抜粋
2-1 Approach(Section2)
2-2 Methodology(Section3)
2-3 Experiments and Results(Section4)
2-4 Related Work(Section5)
2-5 Discussion and Conclusion(Section6)
3. まとめ