XAIの概要を把握する|LIMEとSHAPの手法の確認 #2
当シリーズではXAIの研究の概要の把握を行います。#1ではSurveyを元に大まかな体系の確認を行いました。
#2では汎用的に用いることの可能なModel-Agnosticな手法であるLIMEやSHAPに関して、それぞれの論文を元に確認を行います。
[1602.04938] "Why Should I Trust You?": Explaining the Predictions of Any Classifier
[1705.07874] A Unified Approach to Interpreting Model Predictions
以下が目次となります。
1. LIMEの概要
2. SHAPの概要
3. まとめ
1. LIMEの概要

上記はLIMEの論文のSection3の冒頭部ですが、LIMEは"Local Interpretable Model-agnostic Explanations"の略であることが確認できます。"agnostic"は#1で取り扱いましたが、「ソフトウェアやハードウェアが特定のシステムに依存しないこと」を意味します。
また、ここでの"local"は「ある特定のサンプルの近傍(vicinity)」という意味であり、関数のテイラー展開と同様に理解すると良いと思います。
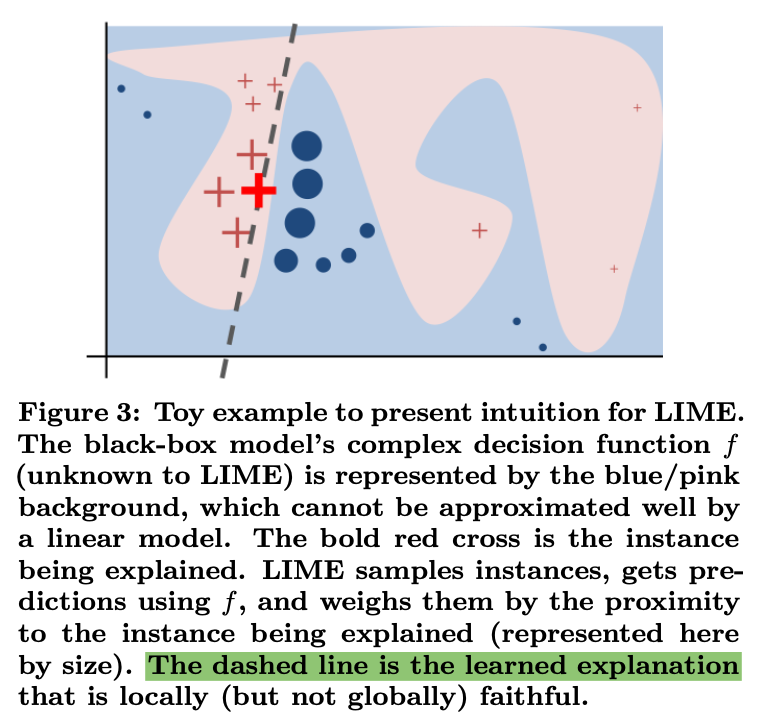
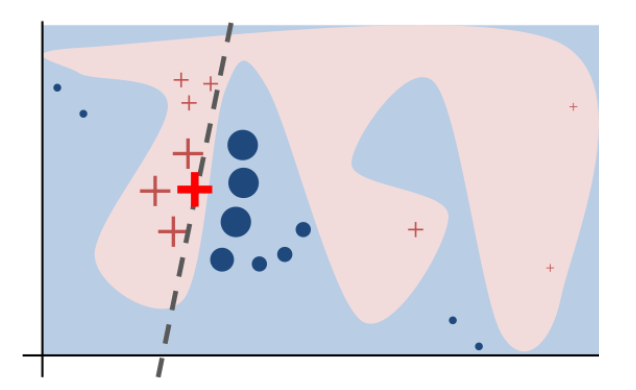
LIMEの概要に関しては上記のLIMEの論文のFigure.3を確認するとわかりやすいです。赤と青の領域が分類結果の際に、bold体の赤の×の近傍のサンプルの予測結果を元にグレーのdashed lineを学習し、これによって解釈を行います。

Figure.3のようなLIMEの学習結果の作成にあたっては、上記で定義されるlocality-aware lossのと、
の複雑さ(complexity measures)を表す
を用います。
ここで複雑なを、特定のサンプルの近傍の予測結果に基づき、linear modelのような単純な
で近似を行うというのがLIMEの概要です。

また、特定のサンプルの近傍の値の生成は、上記のように乱数などを用いて近傍の入力を生成し、それをで予測した結果を元に
の学習を考えます。この考え方は摂動(perturbations)と表されることも多いので抑えておくと良いと思います。
ここまでの内容を元に、LIMEの手順をまとめると下記のようになります。
① 摂動によって特定のサンプルの近傍の入力値を作成
② 解釈対象のを用いて入力値を予測
③ ①で生成した入力と②で生成した出力の組を元に、locality-aware lossのとcomplexity measuresの
を基準に
で

また、locality-aware lossで用いられているは上記で示されるように、①で
から摂動によって生成された
の
との類似度(proximity measure)を表すと理解すると良いです。
ここまでの内容でLIMEの手順について確認を行いましたが、LIMEの概要をまとめるなら「複雑なを特定のサンプル
の近傍の
の予測結果
を元に、シンプルな関数
を学習し、
を元に
の解釈を行う」と理解すると良いと思います。
2. SHAPの概要

上記がSHAPの論文のAbstractですが、SHAPは"SHapley Additive exPlanations"の略で、ゲーム理論におけるShapley Valueの知見を元に特徴量に関して加法的な(additive)説明を行うというのがSHAPの概要です。
additiveと表されると難しく見えますが、単にlinear model以外もlinear modelのようにの形式で統一的に取り扱えるようにShapley Valueの考え方を活用すると理解すれば良いです。
当記事ではまずSHAPの基盤の考え方であるShapley Valueに関して確認します。

Shapley Valueに関しては上記の論文式が理解できれば十分だと思います。式は複雑に見えますが、表記を1つ1つ確認すればそれほど難しくありません。まず、
に関しては
が全ての特徴量の集合を表し、
はその部分集合(subsets)を表します。
また、は
で表した特徴量に特徴量
を加えた際に予測値がどのように変化するかを表します。ここで部分集合
に特徴量
を加えることから、
の下では
以外の
に含まれる部分集合
を用いるとされていることに注意が必要です。
さらにや
はそれぞれの特徴量の要素の数を表すことから、
は
の選び方が多い
に補正をかけると理解すれば良いです。
このように特徴量の効果の
を
式のような重み付け和によって計算することで、それぞれの特徴量の効果の計算を行います。

それぞれの計算の結果は上記のFigure.1のように図示されます。このように考えることでlinear model以外の手法を用いていてもlinear modelのような解釈を行うことができ、大変有用です。
3. まとめ
#2ではLIMEとSHAPに関して取り扱いを行いました。
#3ではDeepLearningに関するXAIの手法に関して取り扱いを行います。