Pandasとmap|Pythonにおける処理高速化をラフに考える #3

このシリーズではPythonの処理高速化についてラフに取り扱っています。
#2ではmapと繰り返し文(for)について簡単に取り扱いました。
#3ではPandasとmapについて取り扱います。
以下、目次になります。
1. mapを用いたPandasのカラムの置換
2. map、lambdaを用いた処理
3. まとめ
1. mapを用いたPandasのカラムの置換
1節ではmapを用いたPandasのカラムの置換について行います。まず、データフレームを用意する必要があるので、scikit-learnにプリインの"iris"を用いることにします。下記を実行してください。
import pandas as pd
from sklearn.datasets import load_irisiris = load_iris()
iris_data = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_data["target"] = iris.target

実行結果にはいくつか内容確認のためのコマンドを入れておきましたので、気になる方は利用して見てください(本題とは違うのでコードは記載しませんでした)。
さて、上記でロードした"iris"を元に目的変数の"target"の置換処理を行ってみようと思います。まずはfor文とif文を組み合わせた基本的なプログラミングとして実装してみます。
%%time
iris = load_iris()
iris_data = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_data["target"] = iris.targetfor i in range(iris_data.shape[0]):
if iris_data['target'][i]==0:
iris_data.loc[i, 'target']='setosa'
elif iris_data['target'][i]==1:
iris_data.loc[i, 'target']='versicolor'
elif iris_data['target'][i]==2:
iris_data.loc[i, 'target']='virginica'
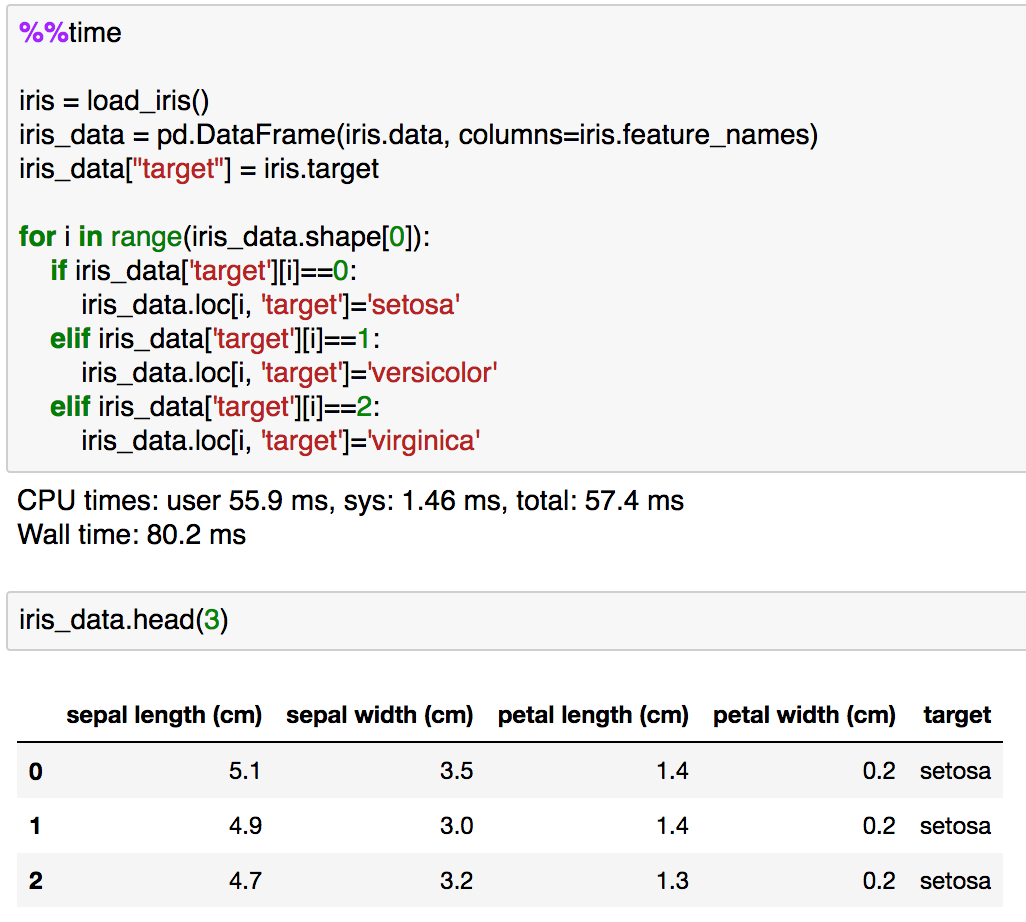
実行結果では"target"がインデックスからカテゴリ名に置き換わっているのが確認できるかと思います。ちなみにこの際に"loc"を用いているのは、そのまま代入しようとすると"SettingWithCopyWarning"が生じたためです。この辺はPandasの仕様上の問題でそのうち変わる可能性もあるので単に"Warning"が出ないようにしただけだとご理解いただけたらと思います。
for文とif文の処理が確認できたので、次はmapを用いた置換処理を実行してみます。Pandasのメソッドとしてのmapを用いた処理では辞書型を与えることで置換処理が可能なのでそちらを用いるものとします。
%%time
iris = load_iris()
iris_data = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_data["target"] = iris.targetiris_data['target'] = iris_data['target'].map({0: 'setosa', 1: 'versicolor', 2: 'virginica'})
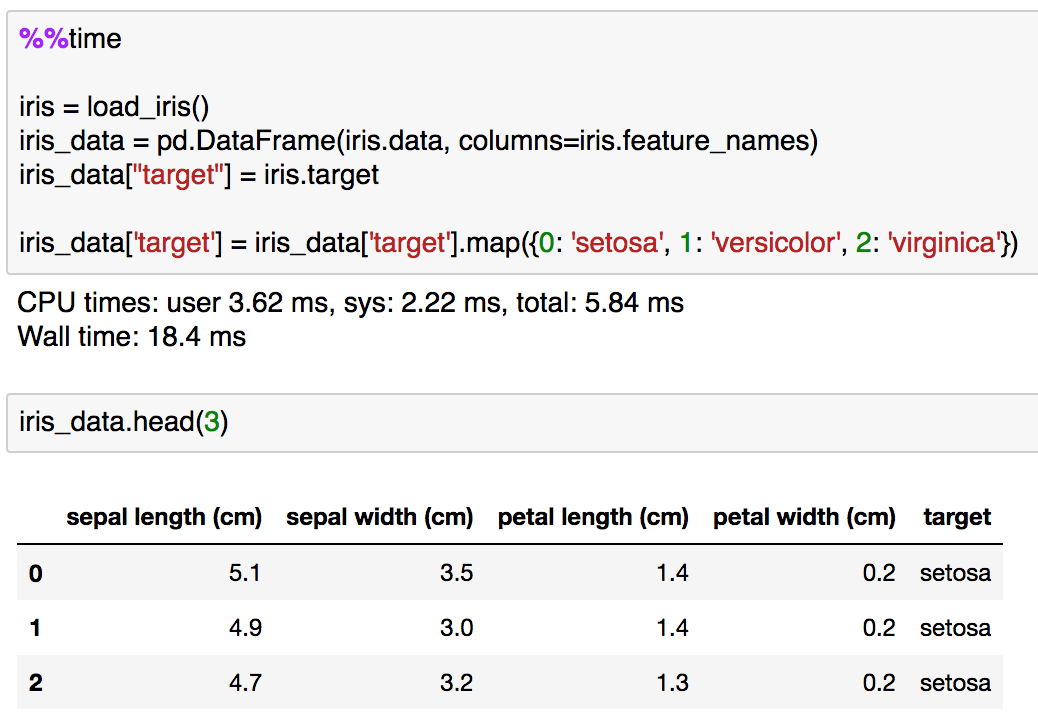
実行結果は同じですが、処理速度がかなり高速化されており、15分の1程度で実行が終了しています。高速化の度合いについてはあまりあてにしない方が良さそうですが、ある程度このように記載する方が高速化すると把握しておく分には問題なさそうです。
Pandasの形式におけるmapを用いた置換処理については簡単に確認ができたので、1節はここまでとします。
2. map、lambdaを用いた処理
1節ではmapに辞書型のオブジェクトを与えることで置換処理を記述しましたが、2節ではmap、lambdaを用いて処理を記述してみます。以下、"petal width (cm)"のカラムに値を加える処理について取り扱ってみます。
%%time
iris = load_iris()
iris_data = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_data["target"] = iris.targetfor i in range(iris_data.shape[0]):
iris_data.loc[i, 'petal width (cm)'] += 1

まず、for文を用いた処理の実行結果は上記のようになります。1節の置換処理と大体同様の処理時間であることが確認できます。
次にmapとlambdaを用いて同様の処理を記述してみます。
%%time
iris = load_iris()
iris_data = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_data["target"] = iris.target
iris_data["petal width (cm)"] = iris_data["petal width (cm)"].map(lambda x: x+2)

実行結果は上記のようになります。1節と同様、15分の1程度の処理時間であることが確認できます。
3. まとめ
#3ではPandasのデータフレームにmapやlambdaを適用した例について確認を行いました。今回の例では15倍ほどの差になりましたが、数字そのものよりもある程度高速化したという理解で一旦は良いのではと思います。
#4ではリストの生成と内包表記について確認します。