Dynamic Headの論文の内容について |物体検出(Object Detection)の研究トレンドを俯瞰する #6
#1〜#5にかけてR-CNN、Faster R-CNN、FPN、RetinaNet、Cascade R-CNNなどについて取り扱いました。
〜
#6ではDynamic Head[2021]の論文について取り扱います。
[2106.08322] Dynamic Head: Unifying Object Detection Heads with Attentions
以下目次になります。
1. 論文の概要の把握(Abstract、Introductionの確認)
1-1 Abstractの確認
1-2 Introductionの確認(Section1)
2. 論文の重要なポイントの抜粋
2-1 Related Work(Section2)
2-2 Our Approach(Section3)
2-3 Experiment(Section4)
3. まとめ
1. 論文の概要の把握(Abstract、Introductionの確認)
1-1 Abstractの確認
1-1節ではAbstractの内容を簡単に確認します。

上記の要旨をまとめると以下になります。
・これまでの物体検出(Object Detection)の研究は様々な手法が開発され、パフォーマンスの向上が試みられてきたが、統合的な見方(unified view)の確立までには至らなかった。
・Dynamic headの論文ではAttentionの考え方に基づいてhead(backbone処理後のfeature mapを元にタスクを解く処理を行う部分)の統合的なフレームワークを示した。
・scale-awareness、spatial-awareness、task-awarenessに基づく複数のself-attentionのメカニズムを組み合わせることで、計算コストにオーバーヘッドを生じさせずにheadの表現力を著しく向上させた。
・記載の設定に基づいてCOCOベンチマークに置いてSotAを実現した。
・作成したcodeが公開された。
Abstractの大まかな要旨を確認できたので1-1節はここまでとします。
1-2 Introductionの確認(Section1)
1-2節ではIntroductionの内容を確認します。重要だと思われるパラグラフを抜粋し、確認を行います。

第一パラグラフでは、物体検出(Object Detection)タスクの概要や主要研究の紹介が行われています。参照論文の11がFast R-CNN、23がFaster R-CNNであることは抑えておくと良いと思います。また、最後の文で「object detection headのパフォーマンスの向上をどのように行うかが重要な課題とされてきた」と言及されており、この論文の問題提起が行われています。


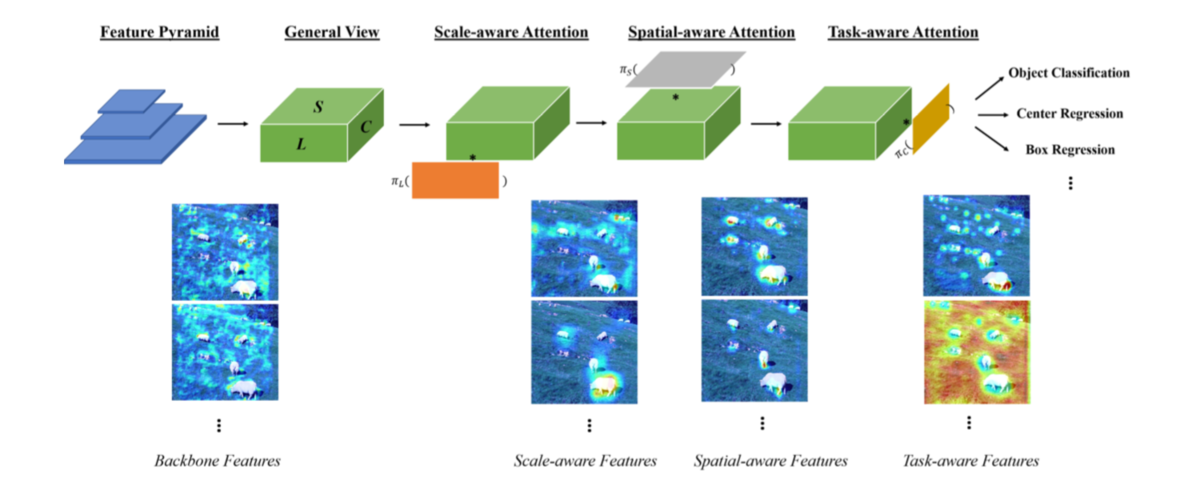
第二パラグラフでは、object detection headの開発にあたっての三つのカテゴリについて記載されており、scale-aware、spatial-aware、task-awareについて紹介されています。詳しくは2-2節で後述しますが、scale-awareはSSDなどで用いられるような異なるサイズのFeature mapの取り扱いについて、spatial-awareは画像上の位置配置について、task-awareはbounding boxやcorner pointsなどのタスクごとの取り扱いについてそれぞれ考えるとされています。


第三パラグラフでは、この論文で紹介するdynamic headではscale-awareness、spatial-awareness、task-awarenessを同時に取り扱うことについて言及されています。それぞれをbackboneネットワークの出力(VGGNetやResNetを用いて作成したFeature mapと同義)をlevel(scale-awareness)、space(spatial-awareness)、channel(task-awareness)の三つの次元を持った3次元テンソルで表すとされています。また、これら三つのawarenessを同時にself-attentionを用いて取り扱うと計算コストがかかるため望ましくないと記載があり、第四パラグラフではその解決にあたってそれぞれを分けて取り扱うことについて言及されています。


第五パラグラフでは行われた実験におけるパフォーマンスに関して記載されています。
2. 論文の重要なポイントの抜粋
2節ではSection2以降の論文の重要なポイントを抜粋して確認します。
2-1 Related Work(Section2)
Section2のRelated Workでは、Scale-awareness、Spatial-awareness、Task-awarenessに関する関連研究についてそれぞれまとめられています。関連研究なので、簡単に流しつつ確認を行います。

(中略)
Scale-awarenessの関連研究でFeature Pyramid Networkが紹介されているので、同様のイメージで考えておくと良いと思います。

(中略)
Spatial-awarenessでは、13がResNet、14がAlexNetの論文のため、基本的なCNNのように空間的な処理を取り扱うと把握しておけば良さそうです。

(中略)
Task-awarenessでは、two-stageとone-stageのトピックなどが紹介されています。23がFaster R-CNN、22がYOLO(You only look once)をそれぞれ参照しています。
2-2 Our Approach(Section3)
Section3のOur ApproachではDynamic Headの研究の仕組みなどについてまとめられています。

上記はSection3-1の記載ですが、Feature mapを元にDynamic Headで用いる特徴量について、数式を用いた記載が行われています。
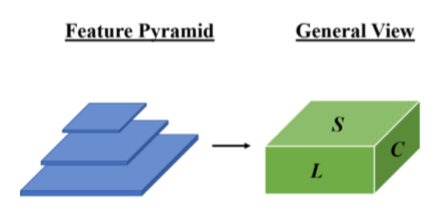
数式を図にするとFigure.1の左上の上図のようになります。ここで注意が必要なのが、Feature Pyramidでは各Feature mapのサイズが異なるので、それぞれに関してリサイズを行う必要があるということです。また、の4次元テンソルでは直感的に理解するのが難しいことから、
を導入し、
の3次元テンソルに変形を行うことについても把握しておく必要があります。

続くSection3-2では、self-attentionの一般的な数式定義について取り扱われています。ここでがattention関数を表すとされており、全結合層(fully connected layer)がattentionに基づくシンプルな手法であると記載されています。一方で単に全結合層(fully connected layer)を用いるだけでは多次元テンソルの処理は計算負荷が大きく、実用的ではないとも記載がなされています。

計算コストの問題の解決にあたって、attentionを三つの連続したattentionの、
、
にわけることについて試みたとされています。これを受けてそれぞれの処理が記載されます。

まずですが、上記のようにattentionが表されています。先にSとCに関しては和を計算し、それぞれの長さで割ることで平均を計算し、
に関するattentionを行うと理解すれば良いと思います。

次にですが、上記のように表現されています。数式定義が唐突にも見えますが、Deformable Convolutional Networksの記法にある程度基づいているのでこちらも合わせて参照すると良いです。
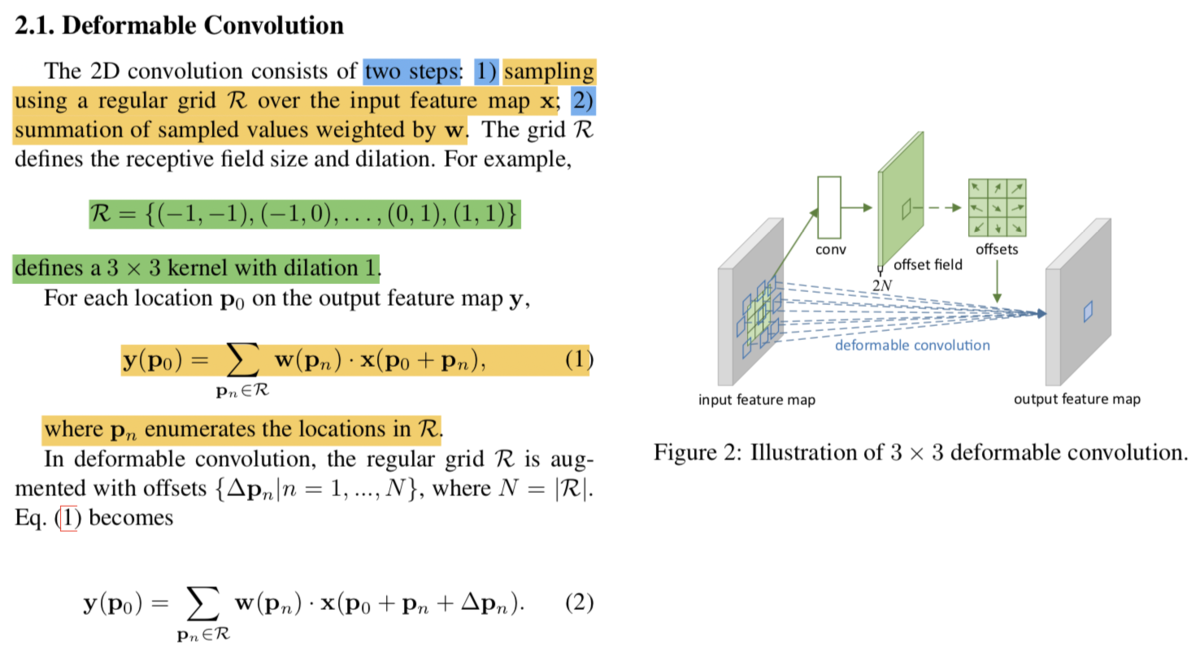
(Deformable Convolutional Networks論文より)

については上記のように記載されています。
2-3 Experiment(Section4)
当記事では省略します。
3. まとめ
#6ではDynamic Head[2021]について取り扱いました。Transformerのようにself-attentionに基づく手法は今後も色々と出てくると思われるので、抑えておくと良さそうでした。