Vision Transformerの実装の確認

上記の記事ではVision Transformerについて論文の確認を行いました。
[2010.11929] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
今回は実装の確認ということで下記を読み解きます。
GitHub - google-research/vision_transformer
以下、目次になります。
1. リポジトリ概要
2. Vision Transformerの実装
3. まとめ
1. リポジトリ概要
1節ではVision Transformerのリポジトリの概要について確認を行います。
GitHub - google-research/vision_transformer
まず、確認するリポジトリは上記になります。こちらのリポジトリは下記のように論文にも実装として記載されています。

(中略)

さて、以下リポジトリについてざっくり確認を行います。
まず、処理概要として上記のように論文と同様の図が用いられています。

次に、必須のライブラリとしてはrequirements.txtに記載されているので、基本的にはこちらを実行しインストールを行います。バージョン関連のエラーなどもあるので、ローカルで環境構築する際は新しくPythonの仮想環境を用意するのが良さそうです。とはいえ、基本的なmodelサイズがBERTに類似しているため、実行環境はある程度検討した上で用意するのが良いかと思います。(ここでは実装の確認がメインなので、動作確認は行いませんでした)

上記のAvailable modelsでは、利用可能な学習済みモデルとして、ViT-B/16、ViT-B/32、ViT-L/16、ViT-L/32、ViT-H/14などが紹介されています。論文確認のところで確認を行いましたが、Base、Large、Hugeとパッチサイズを表しているので、上記に挙げた中ではViT-B/32が一番粗い学習済みモデルであると、理解しておくと良いかと思います。また、コマンドでwgetを用いることでダウンロードを行う際の例として、ImageNet21kで学習させたViT-B_16.npzのダウンロードについて記載が行われています。

次に上記がViTにおけるfinetuningの実行で、実行ファイルがPJ_ROOT/vit_jax/train.pyに記載があることがわかります。

また、実行時のパフォーマンスの期待値は上記のように記載されており、実際にfinetuningを行う際はこちらを参照しつつが良いと思われます。
ここまででVision Transformerのリポジトリの概要については簡単に掴めたので1節はここまでとします。
2. Vision Transformerの実装
2節ではVision Transformerの実装の確認を行います。Vision Transformerの処理の実装についてはPJ_ROOT/vit_jax/models.pyに記載があるので、以下こちらの記載を確認します。(行数はファイルの把握を行いやすいようにあえて表示します。そのうち変更が反映される可能性もありますが大まかな前後関係は関係ないと思われるので、だいたいの実装順序だけ掴むきっかけとしていただけたらと思います。)

vision_transformer/models.py at master · google-research/vision_transformer · GitHub
まず、flax.nn.Moduleを元にしたVisionTransformerクラスの用法として、applyメソッドがメイン処理になるというのは抑えておきましょう。
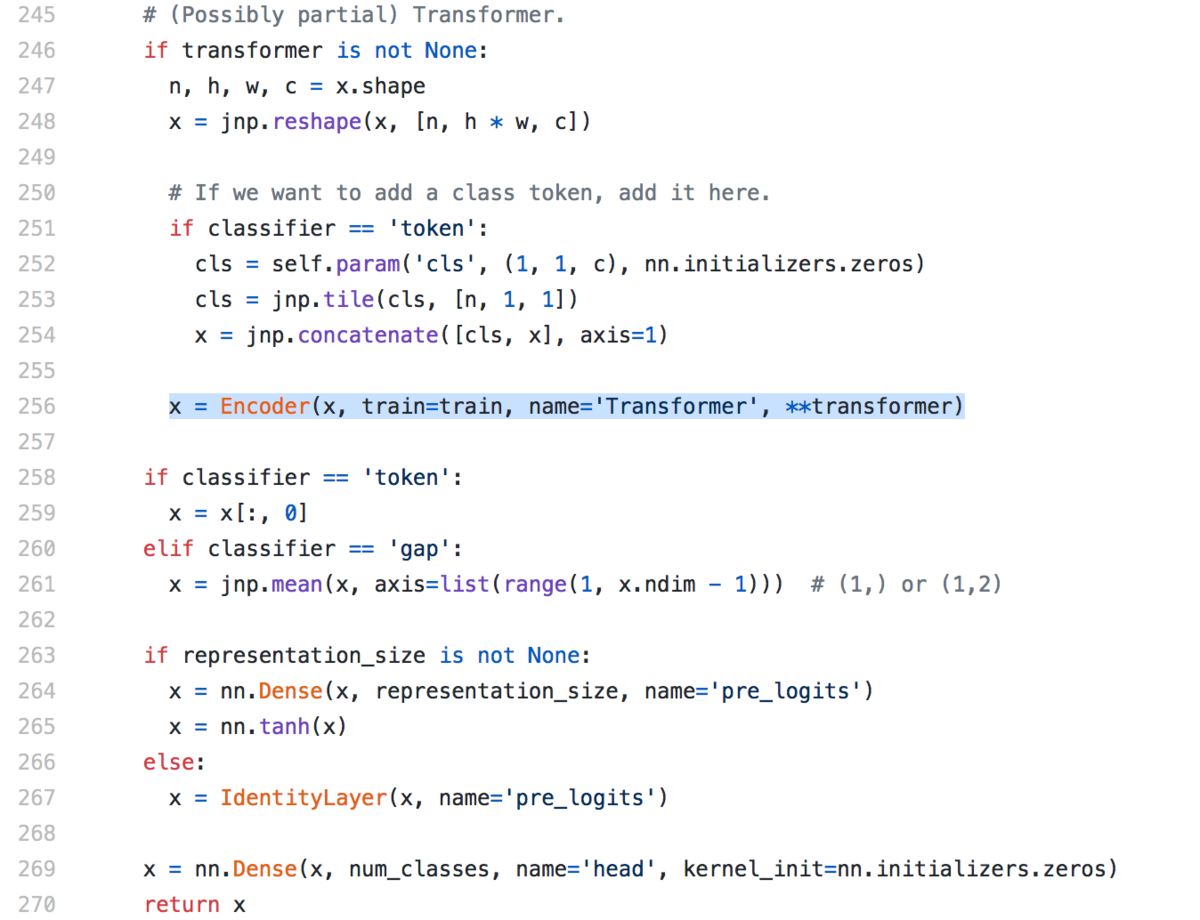
次にVisionTransformerのapplyメソッドの処理の中身ですが、上記のようにViTの処理が記載されています。基本的にはEncoderにViTの処理は記載されています。

(中略)

Encoderクラスのapplyメソッドの処理についですが、大枠としてPosition Embeddingについて取り扱うAddPositionEmbsと、Transformer処理について取り扱うEncoder1DBlockの二つに大別することができます。Transformer処理について取り扱うEncoder1DBlockはnum_layerの数(Baseは12、Largeは24、Hugeは32と考えておくと良い)だけ繰り返し適用していることもここでは抑えておきましょう。

AddPositionEmbsについてですが、上記ではpeを加える処理として実装されています。

(中略)

次にEncoder1DBlockではAttentionとMLPについてそれぞれ実装が行われています。この辺は通常のTransformer処理と同様なのでここでは詳しい確認は省略します。
3. まとめ
今回はVision Transformerの論文記載の実装の確認について行いました。関連でJAXとFlaxはよく見かけたので、こちらも合わせて把握するのが良いかと思われました。(下記などで取りまとめを行うものとします)
動作にあたってはBERTを基本的には踏襲しているため、ある程度同様の環境を用意するのが良いのではと思われました。